The most powerful company in AI might be your electricity provider

If you're using an AI model from a company that owns everything — power generation, datacenter, the chips, the model itself — do you think you're paying less than someone using a provider who rents all of that from someone else?
I've been sitting with this question for a while. And the answer is not obvious until you understand what's actually happening underneath every API call you make. So let's walk through it. One layer at a time.
The product isn't servers. Its reliability.
Most people picture servers, cooling units, and blinking lights. Fair enough. But the product isn't hardware. It's predictability — the guarantee that your workload runs, no matter what. A hospital, a bank, a payments company: they're all paying for the same thing. Certainty that the infrastructure won't let them down at 2 am on a Sunday.
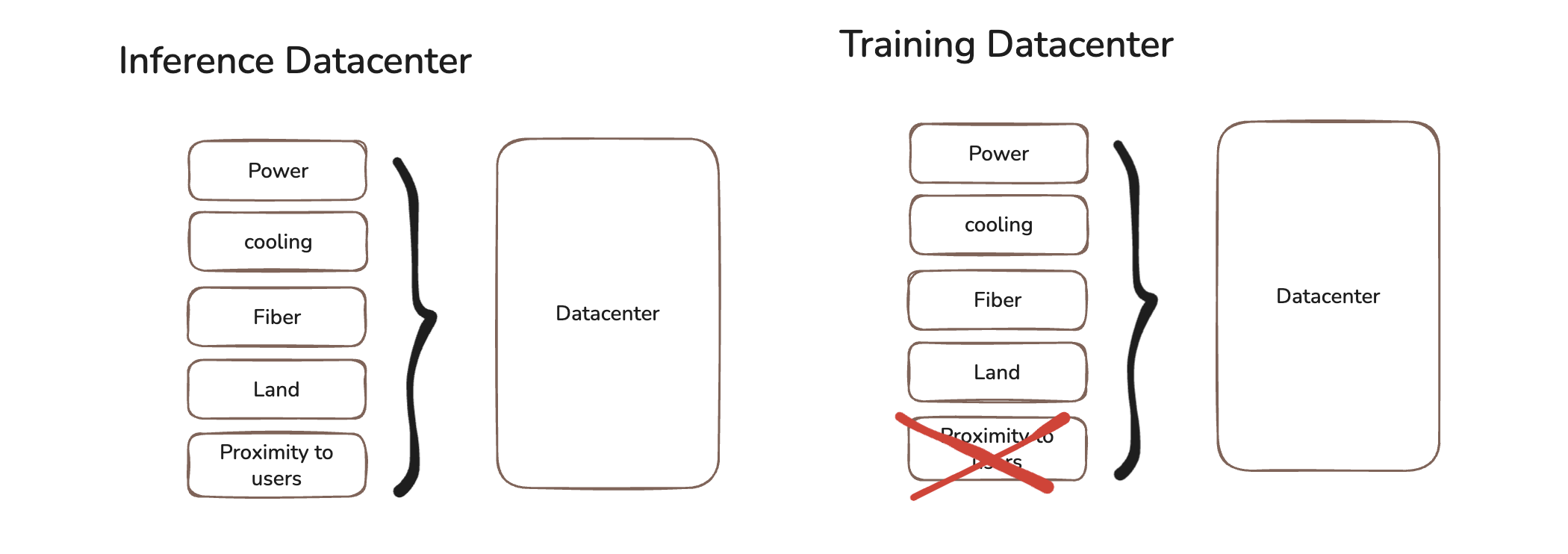
To deliver that, a data center needs five things: land, power, cooling, fiber, and the right GPUs. Each is a real constraint. But they are not equal.
Land is solvable. Rural governments are practically handing it over to attract tax revenue. Fiber takes months to lay. Cooling is an engineering problem with known solutions. These are annoying constraints, not existential ones.
Power is a different problem entirely. And it's the one that actually controls the industry right now.
Forget square footage. Think megawatts.
For a long time, datacenter capacity was measured in physical space — server racks, square footage, floor density. That framing broke when AI showed up.
A single Nvidia H100 GPU draws about 700 watts. A server with eight of them draws 6-7 kilowatts. Scale that to thousands of servers running AI workloads at full tilt, and you're not talking about a building's power needs anymore. You're talking about a small city.
This is why when people say "a 100 megawatt datacenter," they're not describing the building. They're describing the power envelope — the maximum sustained electricity the facility can consume. Everything else is sized around that number.
A rough ladder to anchor the scale:
- 1 to 10 MW: large enterprise or colocation facility
- 100 MW and above: hyperscale, think a major AWS or Microsoft region
- 1 GW (1,000 MW): what xAI, Microsoft, and others are now building for AI
The GPU changed the bottleneck. More GPUs mean more watts. More watts define the facility. It really is that direct.
Getting the power is harder than buying the GPUs
This is the part that surprised me most when I started pulling on this thread.
When a company announces a gigawatt datacenter, the GPUs are almost the easy part. NVIDIA will eventually sell them to you. The genuinely hard part is convincing a utility company to deliver that much electricity to your site.
This process — grid interconnection — means getting physically connected to the power grid at the capacity you need. And right now in the US, there is a queue for this. A long, slow, bureaucratic queue that has no interest in your launch timeline.
The utility has to study your request, approve it, and then build the infrastructure to deliver your power — substations, transmission lines, and the works. That takes roughly 5 to 6 years from the moment you apply. Some projects wait longer.
You cannot buy your way around the queue. There is no workaround. You wait, or you pick a different location.
This is the actual reason tech companies are cutting deals with nuclear power plants. Clean energy is part of it, sure. But a direct connection to a dedicated power source means bypassing the queue entirely. In this environment, that is worth billions.
So the people who already hold permitted, powered, connected land have more structural leverage than anyone building AI software right now. The leverage has shifted from software to infrastructure — and many people in tech haven't fully absorbed that yet.
The math only works at 50 to 60 percent
Building a hyperscale AI facility costs somewhere between $10 and $20 billion before a single workload runs. Land, construction, power infrastructure, cooling, hardware. That's the CapEx — the upfront bet.
Then the doors open. The OpEx begins. Electricity runs around the clock. Cooling that never pauses. Security, operations engineers, and hardware refresh cycles every few years. Unlike the build cost, this never ends.
Here's the uncomfortable part of the math: your CapEx is fixed, your OpEx starts the day you open, but your revenue only arrives when customers show up — which can take months or years after you're live. You're bleeding cash before you've earned a dollar.
And no data center runs at 100 percent utilization. The industry average sits somewhere around 50 to 60 percent. That means you're paying full electricity and cooling bills for infrastructure that is, on average, half idle.
The way you survive this is simple but often misunderstood: you don't price for 100 percent utilization. You price for 50 to 60 percent, recover every cost at that level, and build your margin on top. When a customer pays you, they're not just paying for the compute they used. They're also covering a slice of the idle capacity, the sunk CapEx, and the operational overhead.
That's not greed. That's just the math of running physical infrastructure in the real world.
Training and inference are almost opposite businesses
Not all compute is equal. The two workloads that define AI economics — training and inference — look almost nothing alike.
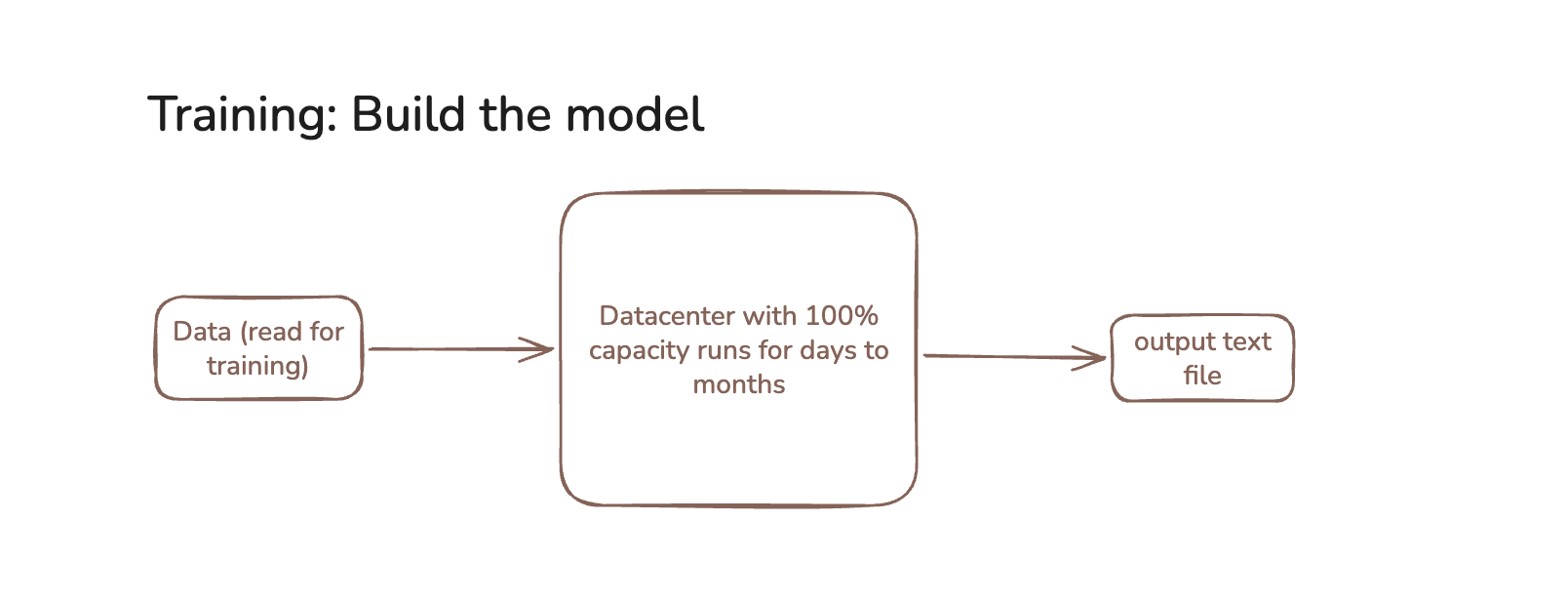
Training is building the model. It runs at near-100 % GPU utilization for weeks or months without interruption. One customer, massive contract, predictable power draw. For a datacenter operator, this is the dream job. The utilization problem disappears. Proximity to end users is irrelevant — you can do this in the middle of nowhere, near cheap power, far from anyone.
Inference is everything after. Every time you send a message to an AI product, that's inference. It runs in milliseconds but happens billions of times a day. The load is spiky and hard to predict — a product can go viral overnight, and the traffic spikes without warning. And unlike training, inference needs to be geographically close to users. Latency matters. A 200ms lag is the difference between a product that feels instant and one that feels broken.
Training is a project. It happens once per model version, and then it's done. Inference is a business — it runs forever and grows every time adoption increases. Every new user, every new product built on the model, every API call is more inference. Long term, that's where the real revenue is.
The catch is that inference is also much harder to operate well. Millions of small unpredictable requests instead of one sustained job. Latency guarantees. Customers who will quietly switch to a faster competitor. The revenue is higher, but it's earned daily, not from a single contract.
Every layer in this stack is charging you a margin
When you use any AI product in the cloud, your request starts at the top and touches every layer on the way down:
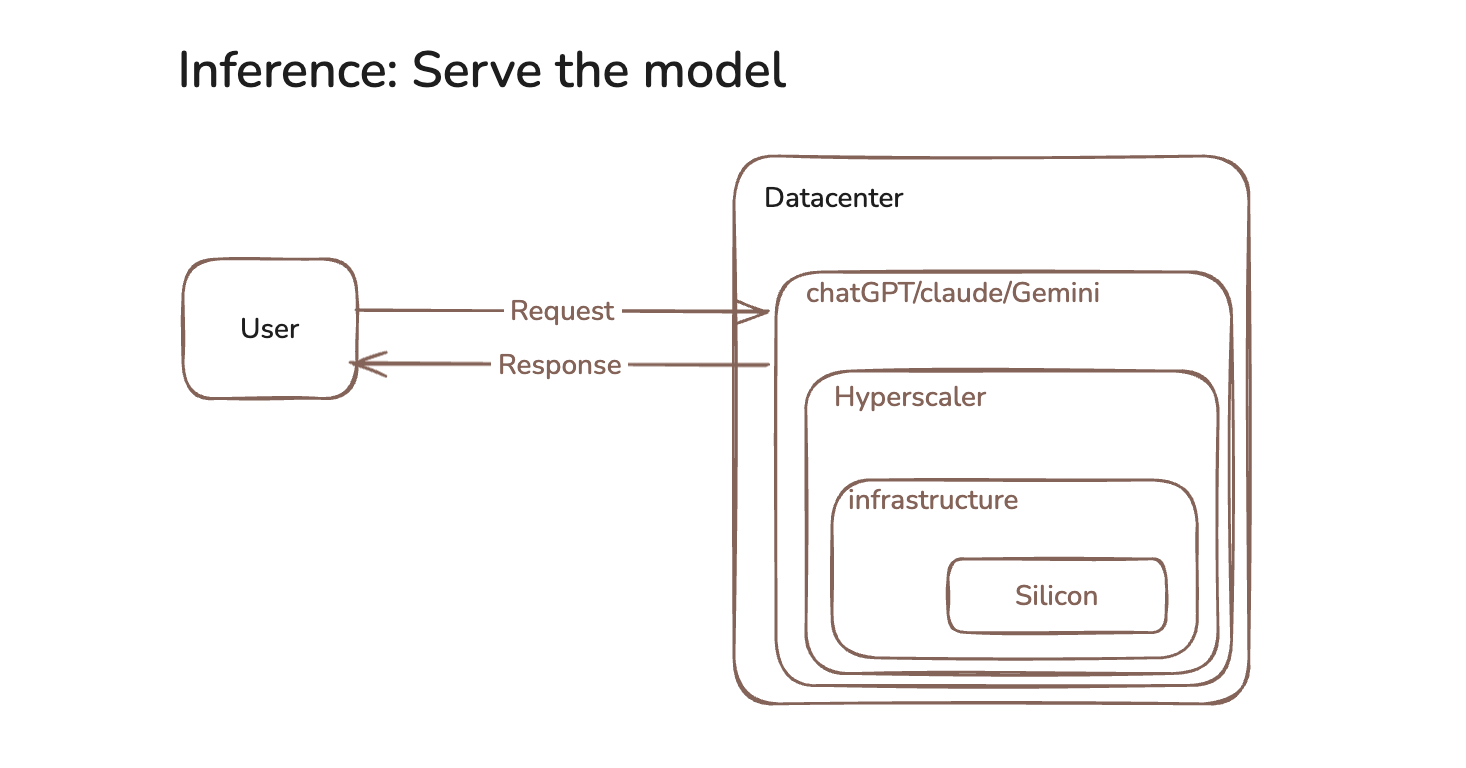
You see the application. You pay the application. But the application is paying the platform, the platform is paying the cloud, the cloud is paying the datacenter, and the datacenter is paying for the silicon and the electricity underneath it. Each layer does real work. Each layer also takes a cut on top of what it paid the layer below.
Cloud providers — AWS, Azure, GCP — sit in a particularly strong position here. They buy infrastructure at a scale that almost no one else can match: negotiated electricity rates, hardware at volume discount, and land in bulk. Then they slice that capacity into tiny units — compute by the hour, storage by the gigabyte, API calls by the million — and sell it to millions of customers at retail.
Here's why the economics work in their favor at scale: when one customer's workload goes idle, another fills the gap. Across millions of customers with diverse workloads running around the clock, utilization tends to smooth out. Their cost per unit drops. Their price doesn't. The difference is margin — and at hyperscaler scale, that margin is the business.
The reason most companies can't replicate this isn't technical. It's scale. Arbitrage only works when you have enough customers to absorb the system's idle capacity.
The companies everyone is watching may be the most exposed
Here's where it gets interesting.
Model companies — OpenAI, Anthropic, and others — are in a genuinely difficult economic position, even if they don't always look like it from the outside.
To build a frontier model, they spend heavily on training. Once that's done, the cost is spent — it's a sunk cost, gone regardless of what happens next. The only way to recover it is through inference revenue. Which means they need users, and they need them continuously, at a growing scale.
But they're paying cloud providers retail prices to serve those users. Which means they're funding the hyperscaler's margin from every dollar they spend on compute. They can't wait 5 years to build their own facilities — the revenue has to flow now. So they rent expensive infrastructure they don't own and pay premiums they can't negotiate away.
Meanwhile, the models themselves are commoditizing faster than most people expected. When several providers offer roughly comparable capabilities, users pick on price and convenience. The model company is caught between expensive infrastructure costs below and price-sensitive customers above.
They're not fragile companies. But the ones who survive long-term will likely be the ones who eventually own enough of the stack to stop paying retail for everything underneath them.
Google is the clearest example of what that looks like when it works. They own the undersea cables, the datacenters, the TPUs, and the models. That vertical ownership is exactly why they could release Gemini with significantly more parameters at a lower price point than competitors who are still renting the infrastructure underneath their models.
Back to the opening question
So: if you use an AI product from a company that owns the entire stack — power, datacenter, hardware, model — are you paying less than you would from a provider who rents all of that?
Structurally, yes. Over time, almost certainly.
A vertically integrated provider pays wholesale at every layer rather than at retail. They keep the margin that would otherwise flow to a cloud provider. They price for their own utilization assumptions, not someone else's. Every layer they own is a cost they control rather than a bill they receive.
This is why the companies building physical infrastructure right now — not just shipping software — are making a bet that's ultimately about pricing power. The question underneath all the AI announcements isn't really about models. It's about who controls the physical world those models run on.
Own that, and you set the price. Rent it, and someone else does.
Google figured this out early. While other model companies were racing to build the best model on rented infrastructure, Google was already sitting on decades of owned datacenters, custom silicon, and global fiber. The cheaper, larger models weren't a surprise. They were the inevitable outcome of owning the stack.
This is part of a broader series on how money, systems, and infrastructure actually work — the kind of context that changes how you read the news. If this was useful, the next one goes into how scarcity shapes who wins in technology transitions.
